Introduction
Illozoo.com is an exellent resource for hiring illustrators or using it as an inspiration.
Why cargo collective was failing
When my client first called me, he asked me to add a profile image to an existing artist. He further explained to me that the interface does not support artist image (the one you see on mouse over). I checked to see how it’s being done and to my surprise it was hard-coded in the style sheets. I agreed to maintain the website even though its ‘updating method’ was a terrible practice and I knew the site was living on borrowed time because of that. It was a short-lived, hackey, quick ‘n ‘dirty fix. Like the american economy.
No thumbnails support
 In addition to that, the way Cargo handles thumbnails is, ummm… by not handling thumbnails. What I mean is that the images are loaded full-size and then re-sized on the front-end using CSS. What that results in, is a large page size that takes 5 seconds to fully load for the first time. If you are familiar with images on the web you should know that that is a big No, No. (Unless preloading everything is exactly what you want to accomplish) Take a look here!
In addition to that, the way Cargo handles thumbnails is, ummm… by not handling thumbnails. What I mean is that the images are loaded full-size and then re-sized on the front-end using CSS. What that results in, is a large page size that takes 5 seconds to fully load for the first time. If you are familiar with images on the web you should know that that is a big No, No. (Unless preloading everything is exactly what you want to accomplish) Take a look here!
No user-friendly interface
 Re-arranging the portfolio images was another nightmare. There is no drag-n-drop interface. To make a slideshow you will need to select all the shortcodes for the images (ex {image1},{image2}, etc) and click on slideshow button. That would wrap the shortcodes in another {slideshow} {slideshow/} shortcode. Check it out for yourself.
Re-arranging the portfolio images was another nightmare. There is no drag-n-drop interface. To make a slideshow you will need to select all the shortcodes for the images (ex {image1},{image2}, etc) and click on slideshow button. That would wrap the shortcodes in another {slideshow} {slideshow/} shortcode. Check it out for yourself.
Moto for 2014: No end-user deserves to copy and paste shortcodes to change the order of their portfolio!
No access to back-end code
 Lastly, after a few months of maintaining the website, I was asked to add sortable categories feature. So I eagerly agreed to do it, even though I had no idea how to at the time. I just knew it was on the web, therefore it was possible. Well, Cargo does not provide such feature, so I was at least hoping that I’ll have access to the back-end code of the theme. No such luck. The theme was too old and I was told by cargo that to do this, I’d need to change the theme to a different, newer one (Developer theme). I tried that and it messed up the site pretty entirely. A lot more work would have been required to get the website back to where it was, leave alone the sortable categories. I reverted back to the old theme.
Lastly, after a few months of maintaining the website, I was asked to add sortable categories feature. So I eagerly agreed to do it, even though I had no idea how to at the time. I just knew it was on the web, therefore it was possible. Well, Cargo does not provide such feature, so I was at least hoping that I’ll have access to the back-end code of the theme. No such luck. The theme was too old and I was told by cargo that to do this, I’d need to change the theme to a different, newer one (Developer theme). I tried that and it messed up the site pretty entirely. A lot more work would have been required to get the website back to where it was, leave alone the sortable categories. I reverted back to the old theme.
I didn’t give up just yet. I ended up implementing another quick ‘n’ dirty fix. Below is a jQuery code that has a JSON object array with all the artist’s names and their respective category. It adds class names to the DIVs right before initiation of the isotopes plugin. All on the front-end, all hard-coded.
Adding a new artist now required editing style sheets and javascript code.
I shall name this script: Front-end Categories Script for jQuery Isotopes using JSON Array
var cats = {
'Fashion':
['Cleonique','Ënnji','BOISSON','ENNJI','KABAN','VANHAEREN','Winnel', 'DANAWI','TOMAI','FLORIS','DITTMANN','MULLAN','Ënnji','SOKOLOVA','FIGOWY','NAITO','GREENBERG','JOHNSON','LE CHEVANCE','LANZONE','COOPER','WEBSTER','VANHEREN','RADULESCU','WINNEL'],
'Children':
['Cleonique','GREENBERG', 'CALO', 'RIVOLA', 'PINTOR', 'CRISTINA MARTIN','WESTGATE','GONZALEZ','WESTAGATE','LAURO','DURFEE','WISHBOW','MORGAN','BOISSON','FABER','TOMAI','GIORDANO','KRAVETS','FLORIS','ARGIJALE','WILLIAMS','WESTAGE','BISCUIT','LAURO','WOOD','KABAN','LUEBERT','AJUBEL','POTTER','DOMENICONI','FIGOWY','DGPH','BUNNY','LEE','PAVELIC','CANAVEZES','PARKER','IKONEN','KAKEDA','HABBENINK','RAMON','MAINGUY','JOHNSON','PIUNTI','GRIVINA','TERRY','WEBSTER','RUGGIERI','STOVER','RILEY'],
'Realism':
['Lindsey','STEVE MCDONALD','COLIN MARKS', 'ROMANOS','Winnel ','SCHLICK','FABER','GÜDEL','HONDRU','DITTMANN','WILLIAMS','BITTLER','SOKOLOVA','BURGE','SEIFARTH','DOMENICONI','SEMENOV','SAKODA','LEWIS','MOORE','WINNEL'],
'Design':
['Nick','MENDEZ', 'CRISTINA MARTIN', 'BOISSON','Ënnji','BUNNY','GIORDANO','DANAWI','FRAZIER','ARGIJALE','MULLAN','MANAPOV','WESTGATE','BISCUIT','WOOD','LUEBERT','AJUBEL','POTTER','NAITO','GREENBERG','DENIGOT','DGPH','LAB','OJEDA','SCARELLI','JOHNSON'],
'Editorial':
[ 'Nick','Lindsey','CALO', 'COLIN MARKS', 'RIVOLA', 'PINTOR', 'RAMÓN','SPOZIO','SILVERINI','FABER','GÜDEL','GONZALEZ','GIORDANO','CALCAGNINI','DANAWI','FRAZIER','FLORIS','ARGIJALE','MULLAN','MANAPOV','WESTGATE','BURGE','SEIFARTH','LAURO','KABAN','DURFEE','POTTER','GAJEWSKI','GREENBERG','CANU','FRUITOS','WARAKSA','KRIEK','PAVELIC','IKONEN','DERAMON','MROZIK','MAINGUY','YELLOW','JOHNSON','WISHBOW','LORENTE','BEALS','SAKODA','GRIVINA','COOPER','WEBSTER','RUGGIERI','WANG'],
'Fantasy':
[ 'Nick','Cleonique','STEVE MCDONALD','COLIN MARKS', 'SCHLICK','MROZIK','ROMANOS','SPOZIO','SCHLIK','SILVERINI','FABER','GONZALEZ','CALCAGNINI','DANAWI','HONDRU','DITTMANN','WILLIAMS','BITTLER','SOKOLOVA','DURFEE','SEMENOV','KRIEK','LEE','FANTOM','KAKEDA','MOROZIK','BEALS','LEWIS','PIUNTI','WINNEL','LARSEN','MOORE','DOMBROWSKI'],
'Urban':
['Cleonique','MENDEZ', 'ARGIJALE','MULLAN','BURGE','BISCUIT','DENIGOT','DGPH','BUNNY','OJEDA','CANAVEZES','SCARELLI','WISHBOW','LE CHEVANCE','LANZONE','COOPER','VANHAEREN','RADULESCU'],
'Humorous':
[ 'Cleonique','CALO', 'RIVOLA', 'PINTOR', 'MENDEZ', 'CRISTINA MARTIN', 'MORGAN','BOISOON','GIRODANO','DANAWI','ARGIJALE','WESTGATE','BISCUIT','SEIFARTH','WOOD','LUEBERT','GAJEWSKI','DENIGOT','DGPH','BUNNY','OJEIDA','PAVELIC','CANAVEZES','PARKER','IKONEN','SCARELLI','MAINGUY','WISHBOW','LORENTE','SAKODA','CHEVANCE','GRIVINA','WEBSTER','STOVER'],
'Portraits':
['Lindsey','JOHNSON','SPOZIO','SCHLICK','SILVERINI','TOMAI','GÜDEL','HONDRU','DITTMANN','SOKOLOVA','BURGE','SEIFARTH','CANU','FRUITOS','KRIEK','YELLOW','SAKODA','MOORE','LANZONE','WEBSTER','VANHAEREN','WANG','RADULESCU']
};
$.each( cats, function( key, value ) {
j("#filters").append('<li><a href="#filter" data-option-value=".'+key.toLowerCase()+'">'+key.toUpperCase()+'</a></li>');
$.each(value, function (key2, value2){
j( "#page_1 .project_thumb .text:Contains('"+value2+"')" ).closest('.project_thumb').addClass(key.toLowerCase()); //.css( "border", "1px solid whitesmoke" );
});
});
Why did I choose WordPress?
A) It is user-friendly.
B) There are a lot of plugins that could do exactly what I needed.
C) Because creating my own CMS would take much longer
The easy Part:
Re-creating Illozoo in WordPress
I started by looking for a really simple theme which would get me as close as possible to what I was looking for. Then I went on a plugin shopping-spree!
Here’s what I end up with:
Theme: Hatch – Free, simple, and optimized for mobile.
Plugins:
Easy Gallery – Drag and drop to re-arrange images. One click to delete.
Galleriffic – Creates thumbnails and slideshow. It can even paginate the thumbnails and add play/pause slideshow buttons.
Multiple Post Thumbnails – Self-explanatory. Duh! Provides more than one featured images per post. One for the Artwork and one for the Artist (on mouse over)
Portfolio Post Type – Adds Portfolio Type Posts (So we don’t need to use actual blog posts). Comes with portfolio categories too.
Simple Custom Post Order – Enables user-friendly drag-n-drop re-arrangement/re-ordering of the above Portfolio Post type. (or any other custom-post type)
MP Isotopes – Adds the cool, animated filtering of categories feature. (The plugin didn’t work off the box. Custom jQuery setup was needed)
Team Manager – Used for the WHO section. Add a new member simply by dropping a picture and a title.
—————-
Continued from part 1
Transferring the data (The hard part)
You may think that building the website would be 95% of the work and then transferring the data is like “just a few hours of work”, right?
I thought the same thing right up until I actually got my hands on it.
Doing it manually (aka Dream on Miro!)
 My first thought was: I’ll just do it manually one by one. It can’t be that bad… right?
My first thought was: I’ll just do it manually one by one. It can’t be that bad… right?
Actually, it can be – there are 95 artists with an average of ~36 images per artists (a total of ~3420 images) and each artist has ~3 categories that s/he belongs to. Good luck, have fun!
Nope! Not me! I just HATE doing repetitive work, which I know beyond doubt, the computer can automate and do for me. So, my second thought was: I’ll just use a macros app to record the steps/actions for creating a single artist:
Copying the name; Downloading the images; Creating the artist in WP and pasting the name; Copying the categories and then turning them into checkbox clicks… somehow; Uploading the previously downloaded images; Hit Publish!
Then I’d just hit the play button and let the computer do it all… somehow! (Eat, Sleep, Rave, Repeat) Whatcha think? Do-able? No shot! Mission impossible! I couldn’t get it to create a single artist. Even the artist I originally recorded the actions from… leave alone using those same actions to create a different artist.
I gave up. For a split second I thought of calling my client and saying: “Here’s your new website! I’ve done the first artist for you, now you just need to do the other 94 yourself… ” Hahaha
Doing it like a boss (aka Put your big boy pants on Miro!)

You know this saying “Primates are at their best when cornered”? That’s what happened. I got cornered.
I came up with the following plan:
- Transfer all the images to my server
- Scrape all the artists’ names, image URLs, and categories as a multidimensional JSON array.
- Create a script to insert the artists and assign the images and categories using the data from the array.
Sounds simple, right?
It fucking worked! Blood, sweat, and tears but it worked!
Step1 – Scrape image URLs and name of a single artist
Fortunately, Cargo’s domain policy appears to be Cross-origin resource sharing (CORS) which allows for AJAX calls from different domain.
In the following code I used a hardcoded URL for a single artist. The AJAX request gets a result with all the html from that URL. jQuery can treat the result variable as plain html. That means that you can use $(result).find(‘.project_title’).text(); and it will find that class for you, even though it’s not in your local DOM. Pretty sweet. I output the name as H1 and put the images into a div just to test it here.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<script src="./single-ajax-parser2_files/jquery.min.js"></script>
<style>img{width: 200px; height: auto;}</style>
<script>
$(document).ready(function(){
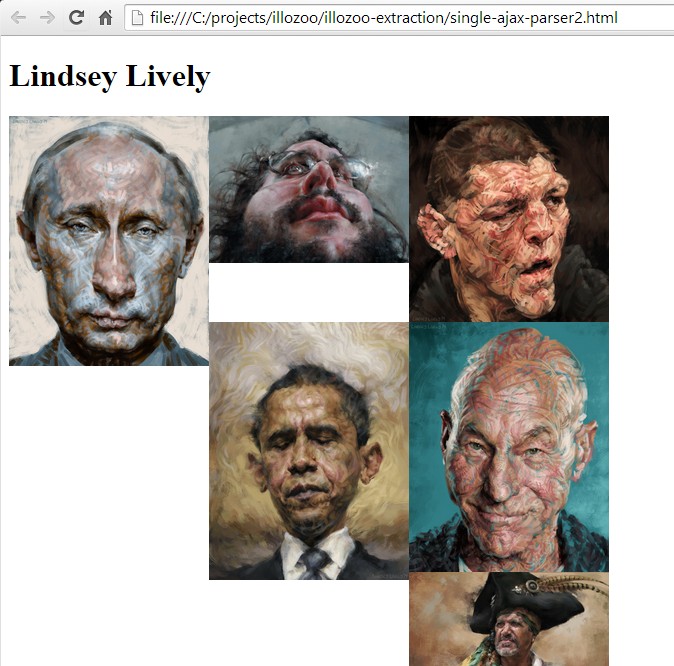
$.ajax({url:"http://cargocollective.com/illozoo/Lindsey-Lively",success:function(result){
title = $(result).find('.project_title').text();
$('body').prepend('<h1>'+title+'</h1>');
slideshow = $(result).find('#slideshow_container');
$("#slideshow").html(slideshow);
}});
});
</script>
</head>
<body>
<div id="slideshow"></div>
</body>
</html>
Here’s a working demo of the above script: (won’t work if the website is no longer live)
View Demo - jsFiddleHere’s the result:
Step 2 – Get the URL of each artist
Time to get the links to each artist. (Then we’ll run the script from step 1 for each link in step 3.)
That was pretty simple. I made a copy of the homepage on my local machine and added a jQuery script at the bottom of it. Now that I think about it, I could have just copied the script and use RegEx.
Anyways, Here’s the script I added to get the URLs:
<textarea id="result"></textarea>
<script type="text/javascript">
jQuery(document).ready(function($) {
/*Small Function Which Capitalizes the First Letter of Each Word */
String.prototype.toProperCase = function () {
return this.replace(/\w\S*/g, function(txt){return txt.charAt(0).toUpperCase() + txt.substr(1).toLowerCase();});
};
/*Find each artist and get the url*/
$('.isotope-item').each(function(index, el) {
el = $(el);
var el_name = el.find('.text').text().toProperCase();
var el_classes = el.removeClass('project_thumb isotope-item').attr('class');
var el_url = el.find('a').attr('href');
var el_art = el.find('.cardimgcrop img').attr('src');
$('#result').val($('#result').val()+'http://www.illozoo.com'+el_url+"\n");
console.log('http://www.illozoo.com'+el_url+"\n"); //This didn't work because it was hard to copy
});
});
</script>
Here’s what I got as a result: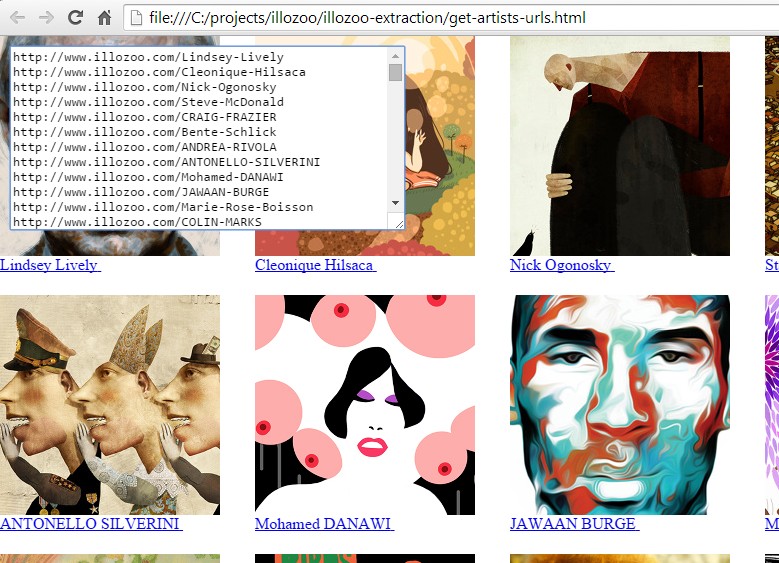
Step 3 – Scrape data from all the artists
Time to run the script from step 1 recursively, feeding it with the URLs we gathered from step 2 and push() the data into an array instead of output it as html:
<!DOCTYPE html>
<html>
<head>
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js"></script>
<script src="tojson.js"></script>
<style>
body{
font-size: 3px;
}
img{
width: 20px;
}
</style>
<script>
$(document).ready(function(){
String.prototype.toProperCase = function () {
return this.replace(/\w\S*/g, function(txt){return txt.charAt(0).toUpperCase() + txt.substr(1).toLowerCase();});
};
/*
//I was testing my script with a single artist just to make sure scrape() will run smooth.
$("button").click(function(){
scrape('http://www.cargocollective.com/illozoo/Kelsey-GARRITY-RILEY');
});
*/
sites = ['http://cargocollective.com/illozoo/Kelsey-GARRITY-RILEY', 'http://cargocollective.com/illozoo/JOHNNY-DOMBROWSKI', 'http://cargocollective.com/illozoo/Ionut-RADULESCU', 'http://cargocollective.com/illozoo/YIQIAO-WANG', 'http://cargocollective.com/illozoo/Kellan-STOVER', 'http://cargocollective.com/illozoo/ALBERTO-RUGGIERI', 'http://cargocollective.com/illozoo/BRAM-VANHAEREN', 'http://cargocollective.com/illozoo/Kyle-T-Webster', 'http://cargocollective.com/illozoo/WILL-TERRY', 'http://cargocollective.com/illozoo/Amanda-LANZONE', 'http://cargocollective.com/illozoo/T-Dylan-Moore', 'http://cargocollective.com/illozoo/Mary-LARSEN', 'http://cargocollective.com/illozoo/Oxana-Grivina', 'http://cargocollective.com/illozoo/ELIZABETH-WINNEL', 'http://cargocollective.com/illozoo/DAVY-Le-CHEVANCE', 'http://cargocollective.com/illozoo/MARCO-PIUNTI', 'http://cargocollective.com/illozoo/Matthew-Lewis', 'http://cargocollective.com/illozoo/Marcus-SAKODA', 'http://cargocollective.com/illozoo/Elizabeth-BEALS', 'http://cargocollective.com/illozoo/INMA-LORENTE', 'http://cargocollective.com/illozoo/Pam-WISHBOW', 'http://cargocollective.com/illozoo/BEE-JOHNSON', 'http://cargocollective.com/illozoo/Julia-YELLOW', 'http://cargocollective.com/illozoo/Marie-MAINGUY', 'http://cargocollective.com/illozoo/Rubens-Scarelli', 'http://cargocollective.com/illozoo/Christina-Mrozik', 'http://cargocollective.com/illozoo/David-de-Ramon', 'http://cargocollective.com/illozoo/HABBENINK', 'http://cargocollective.com/illozoo/Aya-KAKEDA', 'http://cargocollective.com/illozoo/Tuomas-Ikonen', 'http://cargocollective.com/illozoo/TYLER-PARKER', 'http://cargocollective.com/illozoo/Julien-Canavezes', 'http://cargocollective.com/illozoo/DAVOR-PAVELIC', 'http://cargocollective.com/illozoo/ROTTEN-FANTOM', 'http://cargocollective.com/illozoo/SEUNG-HEE-LEE', 'http://cargocollective.com/illozoo/Cristobal-Ojeda', 'http://cargocollective.com/illozoo/ERIK-KRIEK', 'http://cargocollective.com/illozoo/ADRIA-FRUITOS', 'http://cargocollective.com/illozoo/CASMIC-LAB', 'http://cargocollective.com/illozoo/Luli-Bunny', 'http://cargocollective.com/illozoo/IVAN-CANU', 'http://cargocollective.com/illozoo/DGPH', 'http://cargocollective.com/illozoo/ANTON-SEMENOV', 'http://cargocollective.com/illozoo/Nicolas-Denigot', 'http://cargocollective.com/illozoo/Karen-GREENBERG', 'http://cargocollective.com/illozoo/SHINPEI-NAITO', 'http://cargocollective.com/illozoo/FERNANDO-FIGOWY', 'http://cargocollective.com/illozoo/PieR-Gajewski', 'http://cargocollective.com/illozoo/ALICE-POTTER', 'http://cargocollective.com/illozoo/AJUBEL', 'http://cargocollective.com/illozoo/Pablo-Luebert', 'http://cargocollective.com/illozoo/NATHAN-DURFEE', 'http://cargocollective.com/illozoo/Leslie-Wood', 'http://cargocollective.com/illozoo/MASSIMILIANO-DI-LAURO', 'http://cargocollective.com/illozoo/Matthias-Seifarth', 'http://cargocollective.com/illozoo/Mr-Biscuit', 'http://cargocollective.com/illozoo/Masha-Manapov', 'http://cargocollective.com/illozoo/Bernard-Bittler', 'http://cargocollective.com/illozoo/brian-williams', 'http://cargocollective.com/illozoo/MICHAEL-MULLAN', 'http://cargocollective.com/illozoo/Arianna-Floris', 'http://cargocollective.com/illozoo/Ovi-Hondru', 'http://cargocollective.com/illozoo/Alex-Westgate', 'http://cargocollective.com/illozoo/Michael-Waraksa', 'http://cargocollective.com/illozoo/Ivan-Kravets', 'http://cargocollective.com/illozoo/Henry-Gonzalez', 'http://cargocollective.com/illozoo/Osvaldo-Gonzalez', 'http://cargocollective.com/illozoo/Benjamin-GUDEL', 'http://cargocollective.com/illozoo/GIULIA-TOMAI', 'http://cargocollective.com/illozoo/PABLO-ROMANOS', 'http://cargocollective.com/illozoo/Rudy-Faber', 'http://cargocollective.com/illozoo/Pau-Morgan', 'http://cargocollective.com/illozoo/DAVID-PINTOR', 'http://cargocollective.com/illozoo/Argijale', 'http://cargocollective.com/illozoo/CALO', 'http://cargocollective.com/illozoo/IKER-SPOZIO', 'http://cargocollective.com/illozoo/Ennji', 'http://cargocollective.com/illozoo/cristina-martin', 'http://cargocollective.com/illozoo/Katarina-Sokolova', 'http://cargocollective.com/illozoo/JOSE-MIGUEL-MENDEZ', 'http://cargocollective.com/illozoo/PAOLO-DOMENICONI', 'http://cargocollective.com/illozoo/Francesco-Calcagnini', 'http://cargocollective.com/illozoo/PHILIP-GIORDANO', 'http://cargocollective.com/illozoo/COLIN-MARKS', 'http://cargocollective.com/illozoo/Marie-Rose-Boisson', 'http://cargocollective.com/illozoo/JAWAAN-BURGE', 'http://cargocollective.com/illozoo/Mohamed-DANAWI', 'http://cargocollective.com/illozoo/ANTONELLO-SILVERINI', 'http://cargocollective.com/illozoo/ANDREA-RIVOLA', 'http://cargocollective.com/illozoo/Bente-Schlick', 'http://cargocollective.com/illozoo/CRAIG-FRAZIER', 'http://cargocollective.com/illozoo/Steve-McDonald', 'http://cargocollective.com/illozoo/Nick-Ogonosky', 'http://cargocollective.com/illozoo/Cleonique-Hilsaca', 'http://cargocollective.com/illozoo/Lindsey-Lively'];
artists = [];
images = [];
count = 1;
//Where the magic happens!
function scrape(theurl){
$.ajax({url:theurl,success:function(result){
title = $(result).find('.project_title').text().replace(/[^a-z0-9\s]/gi, '').trim().toProperCase();
slug = theurl.split("/");
slug = slug[3].toLowerCase();
//$('body').append('<h1>'+title+'</h1>');
slideshow = $(result).find('#slideshow_container');
images = [];
$(slideshow).find('img').each(function(index, el) {
src = $(el).attr('src');
//$('body').append("'"+src+"',"); //This will print out the images urls
//$('body').append('<a href="'+src+'">'+src+'</a>'); //This will make add a link to it
//$('body').append('<img src="'+src+'" />'); //Show the images. DO NOT RUN! Will crash your tab! 3000+ images
images.push(src);
});
//$("#result").html(slideshow);
artists.push( {'artist':{'name':title,'slug':slug,'images':images}} );
//If it reaches the end print the array
if(sites.length == count){
json = $.toJSON(artists);
console.log(json);
document.write(json);
}
count++;
}});
}
// Run each URL trough the scrape() function
$.each(sites, function(index, val) {
scrape(sites[index]);
});
});
</script>
</head>
<body>
<div id="result"></div>
<button>Get External Content</button>
</body>
</html>
View Demo - jsFiddle
Now, we have all the artists names and their images as a multidimensional JSON array. It looks scary when not formatted but if you run it through this json prettifier/formatter it looks much more humanly readable.
View the Json array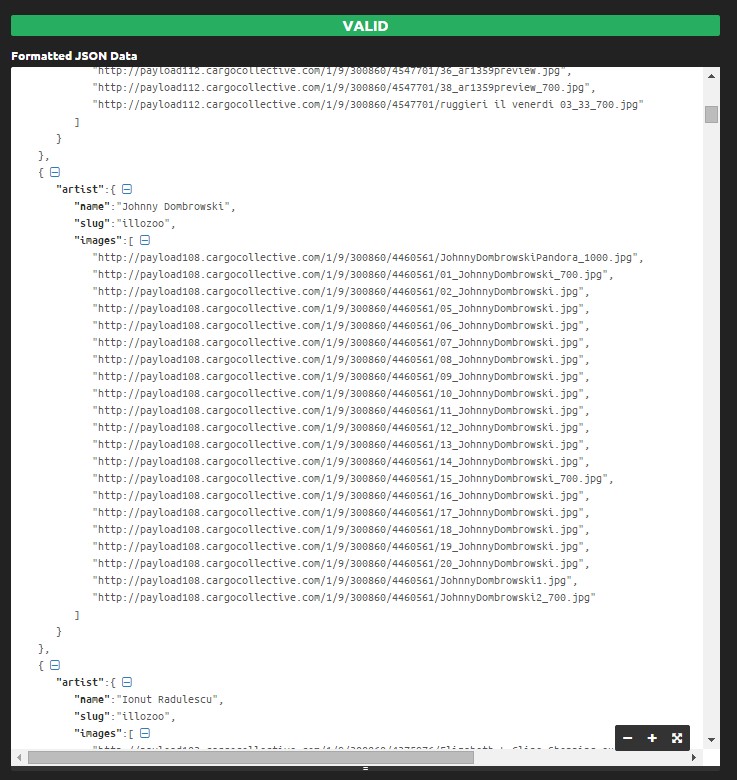
Step 4 – Download the images to my server
Now that we have all the URLs to every image, it’s time to download them to my server at mediatemple. PHP time!
Sidenote: Originally, in step 1, I collected all the images from all artists as one long simple array without knowing which artist the image belonged to. My plan was to just get the images to my server. It worked – but not quite. I ended up being short by approximately 60 images. How did I know that? The array.length (~3420) didn’t match the number of files I had in the folder at the end. On top of that, I didn’t know why. It drove me crazy! It turned out that some of the images had the same name for different artists. Simple names like 1.jpg 2.jpg 3.jpg. etc. Since Cargo uses different payloads (payload108, payload192) same filenames didn’t bother them, but I was downloading all the images in the same folder so the ones with the same names were getting overwritten. Which is why I ended up using multidimensional array with the artists’ names in it. Prior to saving the image on my server I added the name of the artist in front of the file name (as slug). That solved the problem. I was now saving john-smith-1.jpg and jane-doe-1.jpg while they both had just 1.jpg as image name. Still, It was not bullet-proof but what are the chances of having 2 artists with the exact same first and last name and same file-naming habit? (Adding an MD5 hash of the UNIX timestamp seemed like an overkill)
I chopped the array down to just 1 artist and start playing with the code until I got all of that artist’s images on my server.
The following code does 3 things simultaneously. It comes up with a new filename (firstname-lastname_filename.jpg). Then it downloads the image to my server using the new name, and finally it updates the php array with the new name and prints a new JSON array with updated local image filenames instead of remote URLs.
<?php
set_time_limit(0); //Set script execution time to unlimited
//NOTE: I first tested with 1 artist only but when it was working I loaded the entire array from step 3 (It would take up 50 screens of text)
$artists = '[{"artist":{"name":"Ionut Radulescu","slug":"ionut-radulescu","images":["http://payload103.cargocollective.com/1/9/300860/4375976/Elizabeth L Cline_Shopping exces_c1.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/Sandra Newman_Cum sa nu scrii un roman_C1.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR20.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR28.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR27.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR30.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR24.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR22.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR21.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR25.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR16.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR15.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR14.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR13.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR12.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR10.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR11.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR9.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR7.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR6.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/IR3.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/Ionut Radulescu DOR Magazine Editorial Illustration.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/hd_3397e607180f22b6fed3bbb3ce4aac0c_700.jpg","http://payload103.cargocollective.com/1/9/300860/4375976/14b28cd67d3a84fcd1056085fcc48ce3.jpg"]}}]';
$artists = json_decode($artists);
$count=0;
foreach ($artists as $key => &$artist) {
$images = ($artist->{'artist'}->{'images'});
$slug = ($artist->{'artist'}->{'slug'});
foreach ($images as $subkey => &$image) {
$file_ext = basename($image); //Just the filename and extension (image.jpg)
$new_file_ext = $slug.'_'.$file_ext; //Change the file name to firstname-lastname_filename.jpg
$path = 'wp-content/uploads/2014/artworks2/'.$new_file_ext; // Path+New_Filename (Used later)
$image = rawurlencode($image); //Encode the url (didn't work otherwise)
$image = str_replace('%3A', ':', $image); //Bring back the ":"
$image = str_replace('%2F', '/', $image); //Bring back the "/"
// Where the magic happens. Saving/Downloading the image locally from the URL
//file_put_contents( $path, file_get_contents($image) ); //takes ~8sec to complete for 1 artist
copy($image, $path); //takes ~2sec (~4x faster)
//echo $new_file_ext.'<br>';
//sleep(1);
if (empty($path)) {
echo $path.'<br>';
}
$image = $new_file_ext; // Save the new file name on top of the image URL
$count++;
}
echo json_encode($artists); //Print the array with the new names
}
echo $count;
?>
Here’s the new JSON. It’s just like the old one but instead of having names like:
http://payload103.cargocollective.com/1/9/300860/4375976/Elizabeth L Cline_Shopping exces_c1.jpg
They are now just ionut-radulescu_Elizabeth L Cline_Shopping exces_c1.jpg
To be continued… (The WordPress Part)